ChatEarthBench: Benchmarking Multimodal Large Language Models for Earth Observation
* The evaluation server will be publicly released upon the paper's publication.
Abstract
The recent advancements in multimodal large language models (MLLMs) offer new opportunities for Earth observation (EO) tasks by enhancing reasoning and analysis capabilities. However, fair and systematic evaluation of these models remains challenging. Existing assessments often suffer from dataset biases, which can lead to an overestimation of model performance and inconsistent comparisons across MLLMs. To address this issue, we introduce ChatEarthBench, a comprehensive benchmark dataset specifically designed for zero-shot evaluation of MLLMs in EO. ChatEarthBench comprises 10 image-text datasets spanning three data modalities. Importantly, these datasets are unseen by the evaluated MLLMs in our work to enable rigorous and fair zero-shot evaluation across diverse real-world EO tasks. By systematically analyzing MLLM performance across various EO tasks, we provide critical insights into their capabilities and limitations. Our findings offer essential guidance for the development of more robust and generalizable MLLMs for EO applications.
Motivation
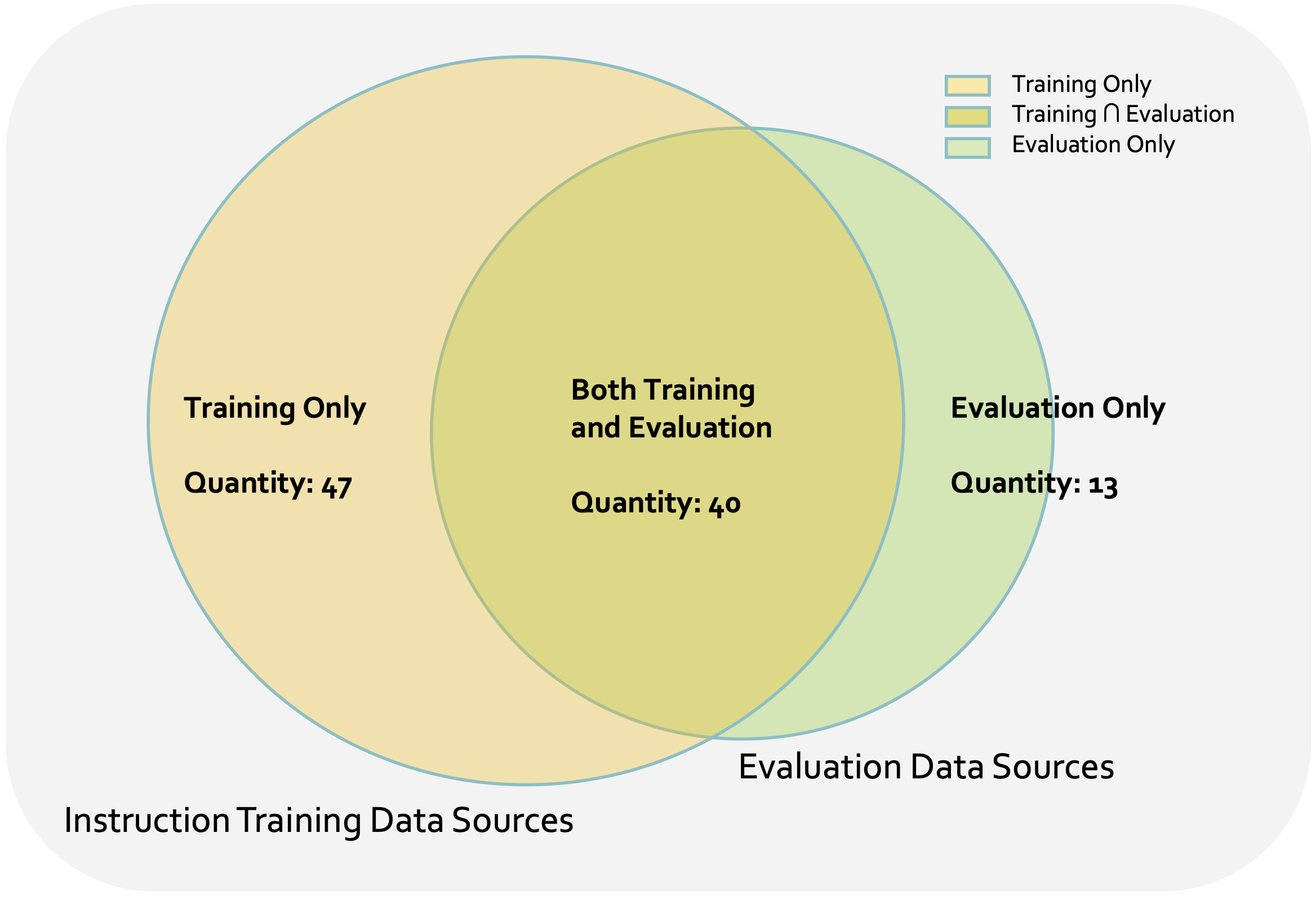
Current evaluations of Earth Observation (EO) MLLMs face a critical challenge: the substantial overlap between training and evaluation data. Existing benchmarks often incorporate samples that models have already seen during training, making it difficult to distinguish true generalization from memorization. Furthermore, variations in training protocols and optimization strategies across studies complicate fair comparisons. The following figure visualizes this data entanglement in representative EO MLLMs. To address these issues, we propose a more rigorous evaluation framework with independent test sets, ensuring unbiased and reliable assessment of model capabilities.
Contributions
We comprehensively analyze datasets across EO MLLMs, revealing critical gaps in current evaluation practices and the challenges posed by dataset overlap between training and testing. Our work shifts focus from architectural innovations to the fundamental issue of fair model assessment.
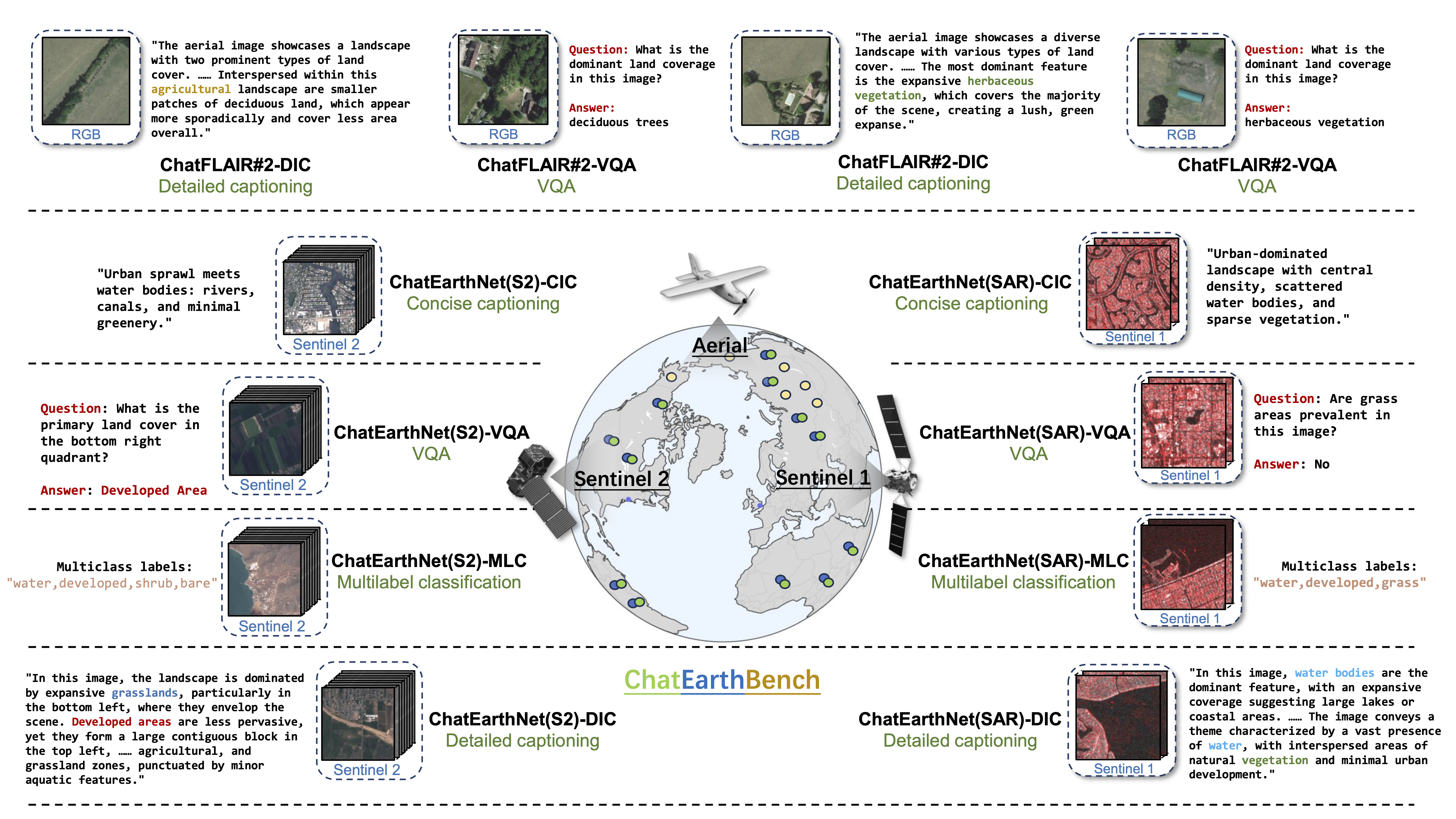
- We introduce ChatEarthBench, a benchmark suite containing 112K image-text pairs from previously unused data sources, enabling real zero-shot evaluation of EO MLLMs. The benchmark spans diverse tasks, including concise/detailed image captioning, VQA, and multilabel classification across different spatial resolutions.
- We conduct a systematic comparative evaluation of 11 MLLMs (both general and EO-specific MLLMs) using ChatEarthBench, providing insights into their relative capabilities and limitations in EO tasks.
- Based on our benchmark results, we identify key directions for advancing EO MLLMs, including expanding EO data modalities, improving model scalability and generalizability, exploring multimodal reasoning, and enhancing reliability and robustness.
Visualization Results
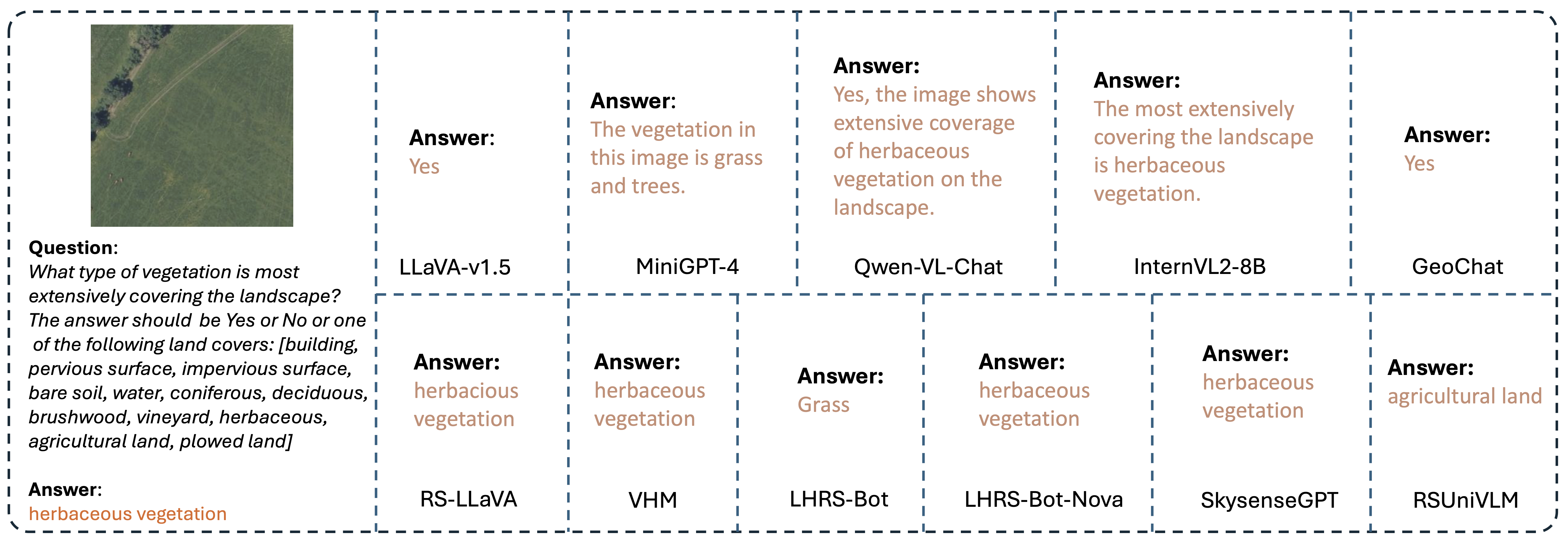
Visualization Result 1
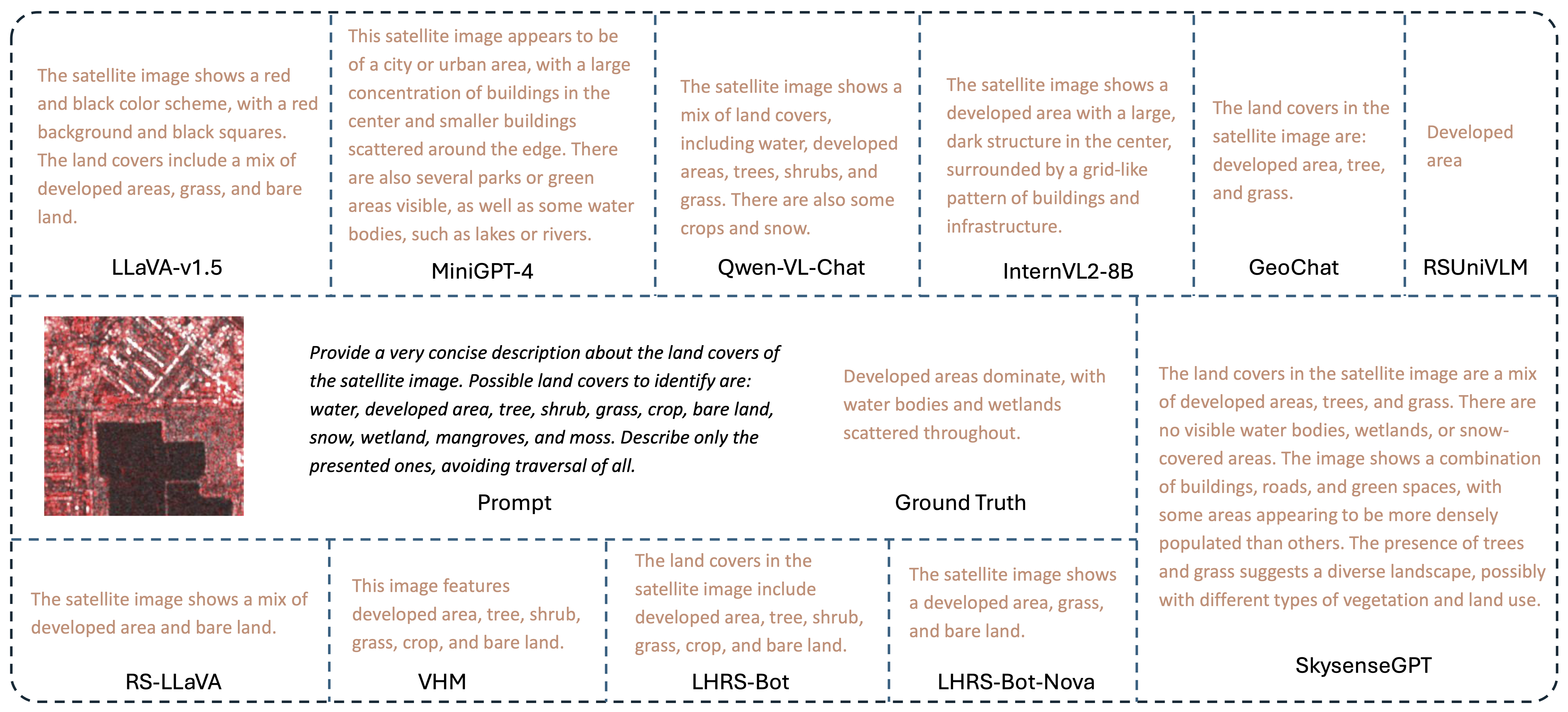
Visualization Result 2
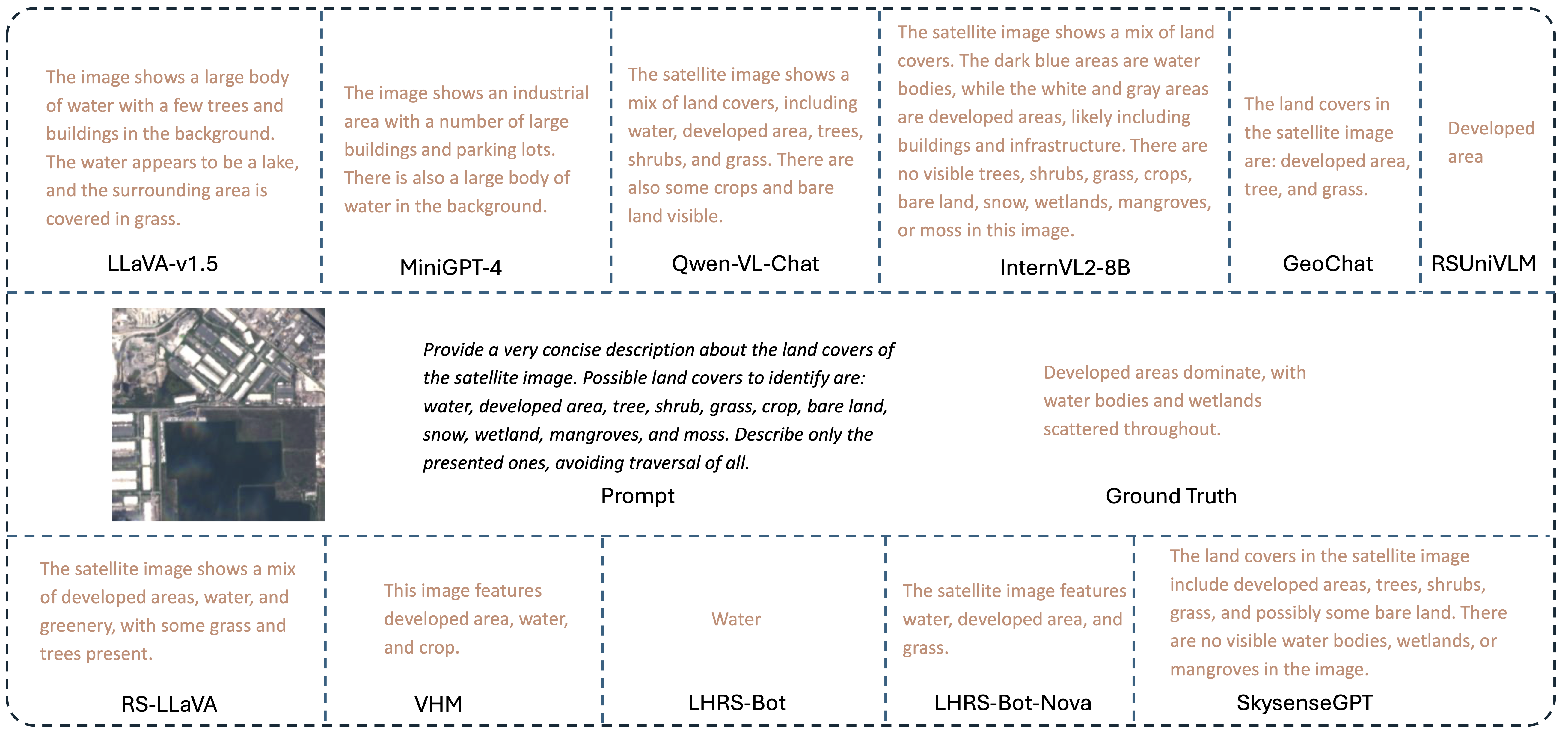
Visualization Result 3
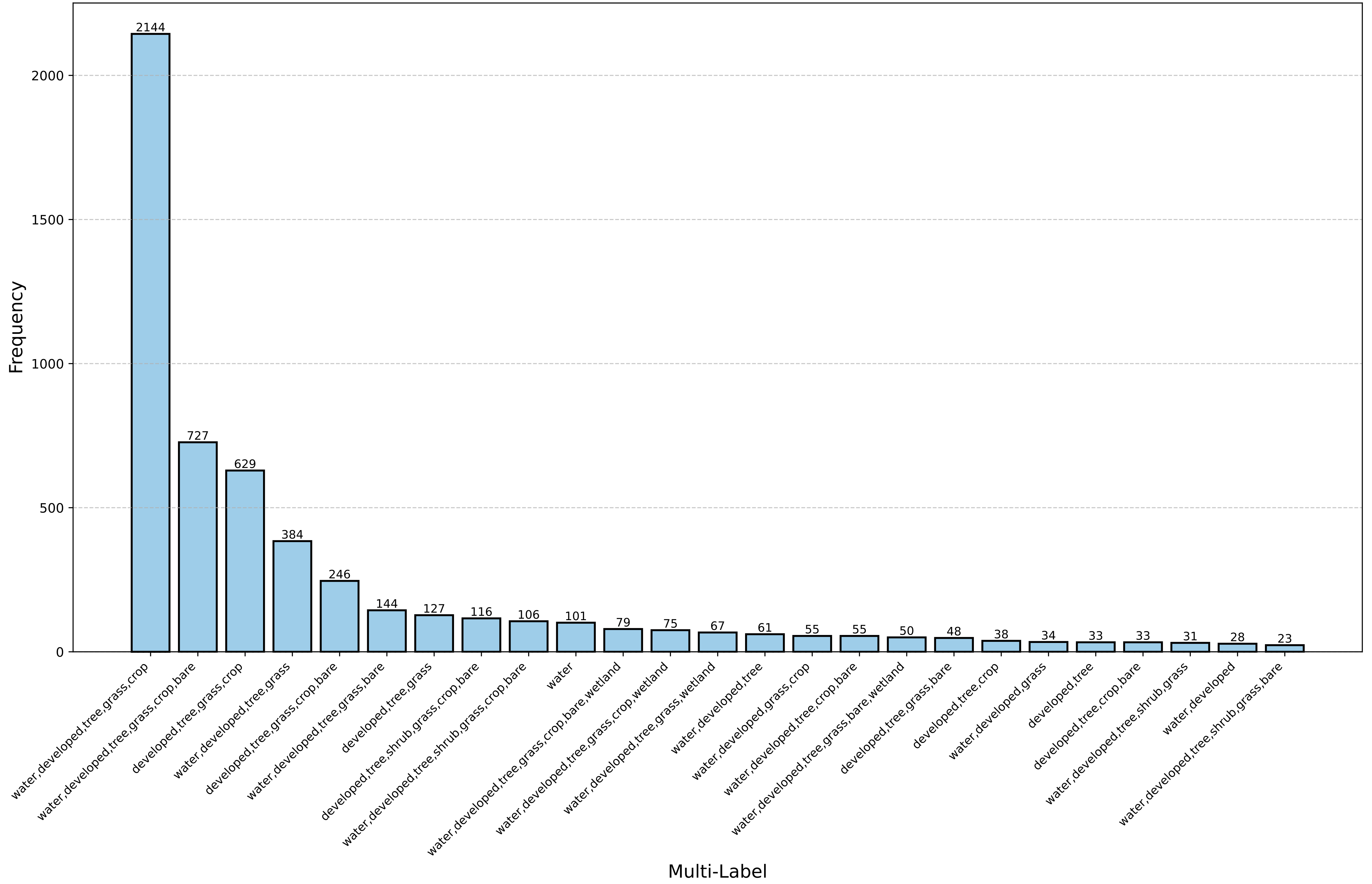
Datasets Statistics
Word Clouds


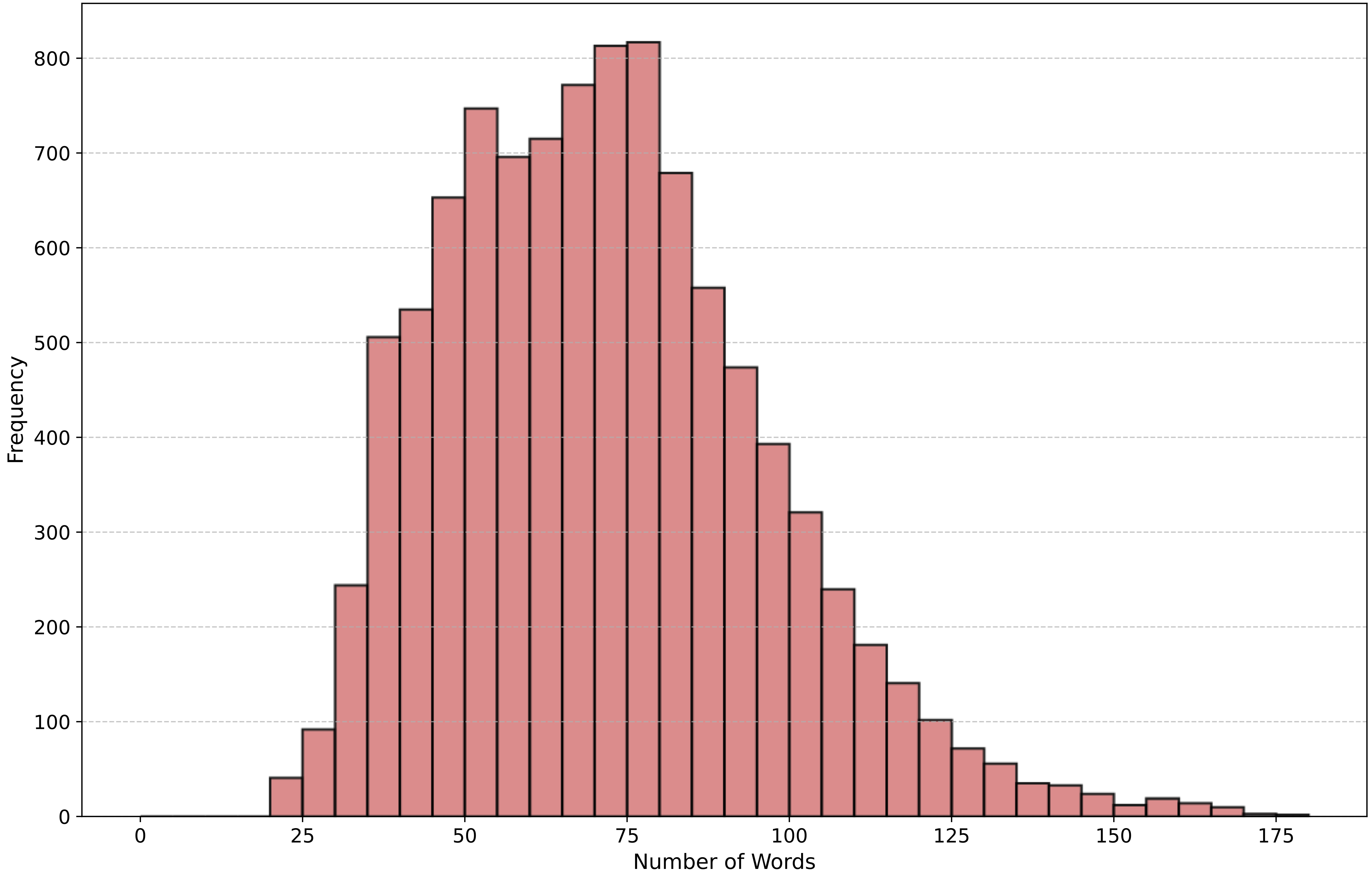
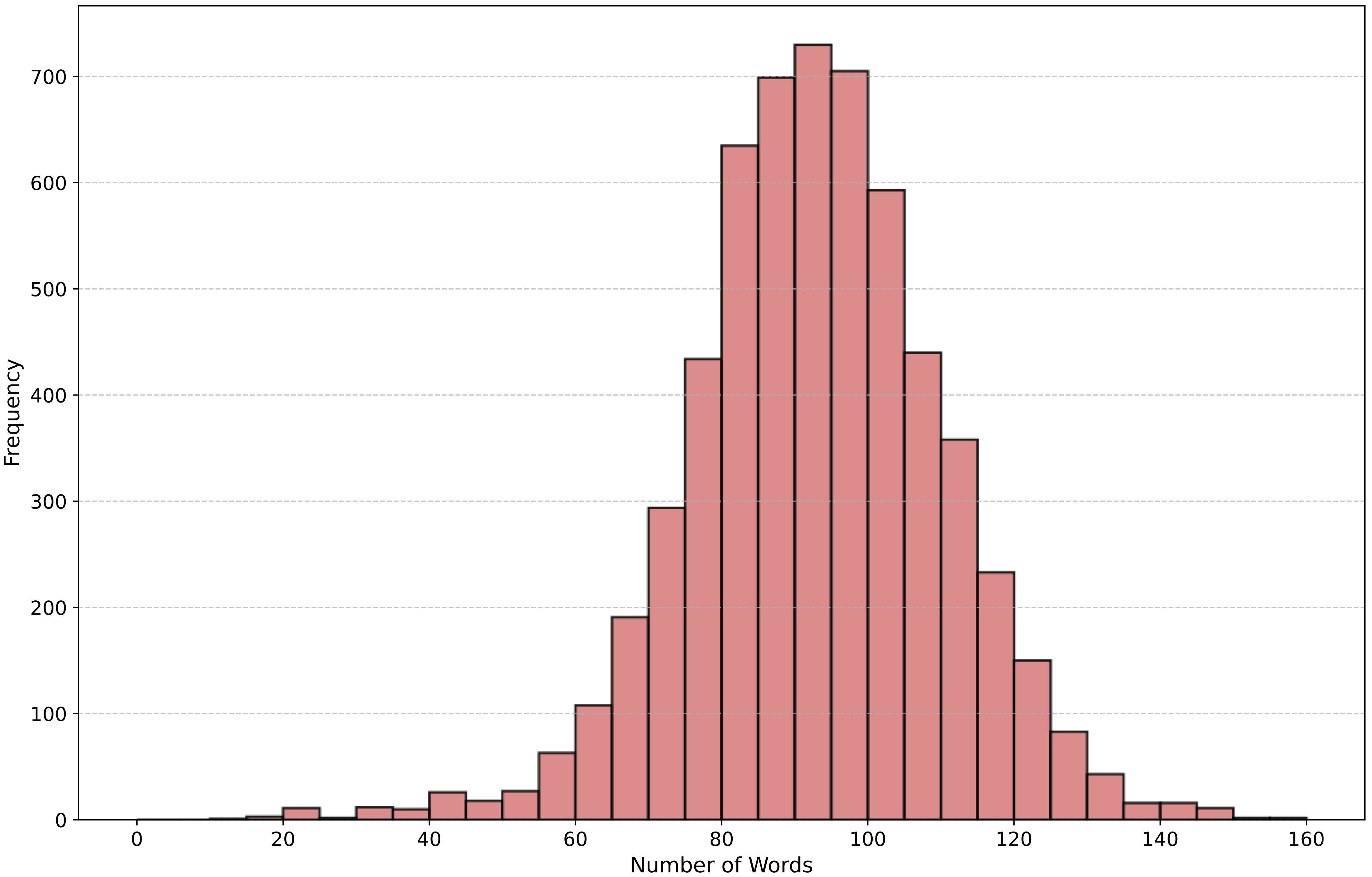
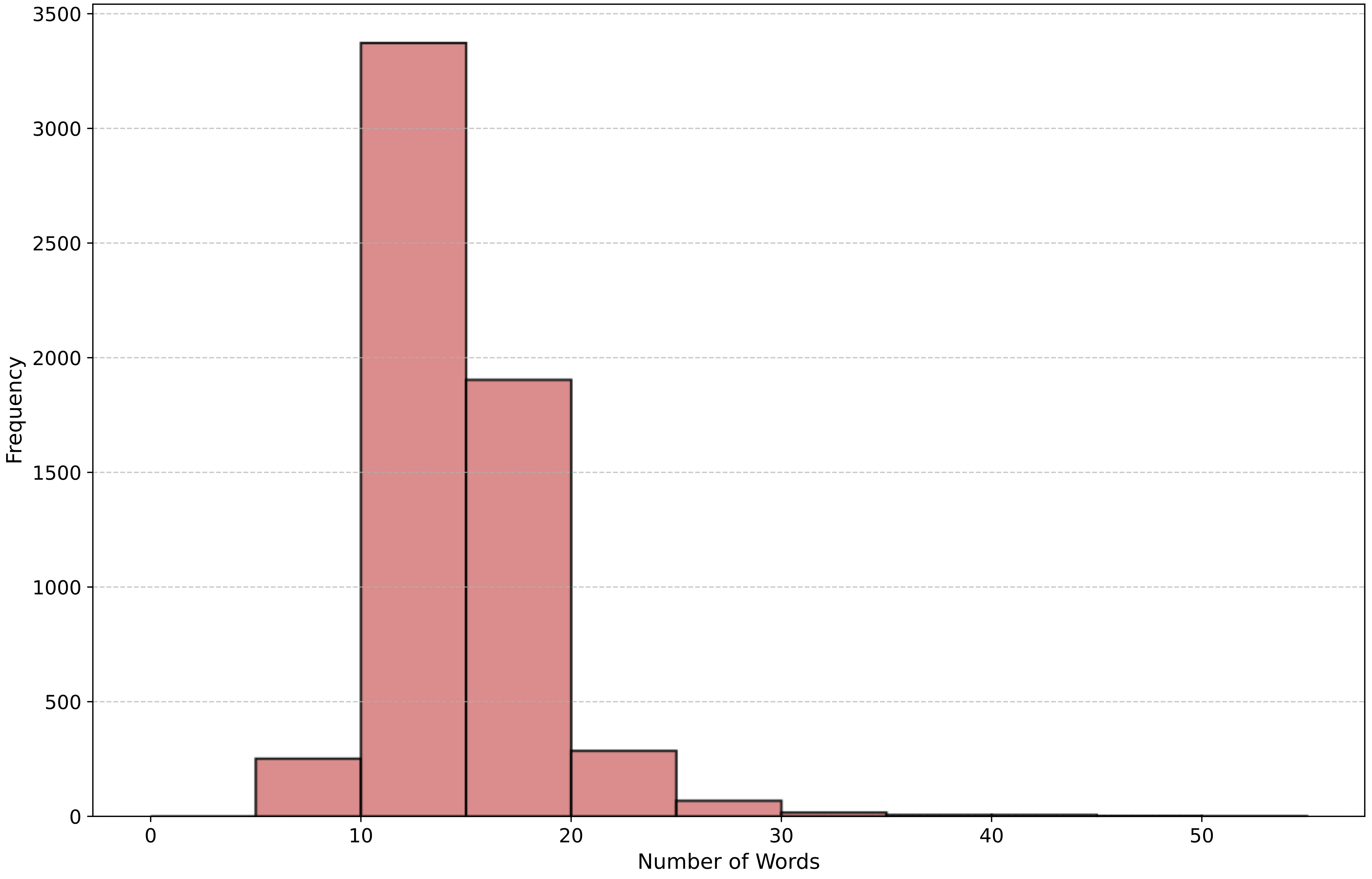
Word Frequency Distributions
Perspectives on the Future MLLMs for EO
Based on our evaluation results, we anticipate several critical aspects that will drive the next generation of MLLMs for EO:
Supported Data Modalities in Earth Observation: Future MLLMs should expand their ability to handle a wider range of EO data modalities. While current models can process optical imagery, next-generation models need to seamlessly integrate additional modalities such as multi-spectral and hyperspectral data. Incorporating these diverse inputs will allow for a more comprehensive understanding of Earth systems and improve performance on complex, multimodal tasks.
Model Scalability and Generalizability: The architectural design of future LLMs should emphasize scalability, allowing for the easy adaptation of models to new EO tasks or datasets. This includes the use of specialized domains of data that can focus on broader aspects of EO data. Researchers should also consider enhancing the in-context learning ability of the MLLMs for deploying these systems in real-world applications.
Multimodal Reasoning: One of the primary challenges in leveraging MLLMs for EO tasks lies in their ability to effectively understand and fuse multimodal data. For instance, enhancing existing MLLMs to integrate both Sentinel-1 and Sentinel-2 data and determining the optimal fusion strategy is critical for improving performance in complex and high-stakes scenarios, such as disaster response.
Reliability and Robustness: Reliability remains a significant challenge for MLLMs in the EO domain. Models should become more robust, particularly in handling noisy or incomplete data, which is common in real-world remote sensing scenarios. Additionally, ensuring that models generalize well across diverse geographic regions and environmental conditions will be key to their practical deployment.
By addressing these aspects and incorporating robust evaluation techniques, the next generation of MLLMs can be better equipped to meet the complex and growing demands of Earth monitoring and analysis.
BibTeX
@article{Yuan2026ChatEarthBench,
title={ChatEarthBench: Benchmarking Multimodal Large Language Models for Earth Observation},
author={Zhenghang Yuan, Zhitong Xiong, Thomas Dujardin, Xiang Li, Lichao Mou, and Xiao Xiang Zhu},
journal={IEEE Geoscience and Remote Sensing Magazine},
year={2026}
}